一段话,讲明白最常用的 5 种压缩算法的原理
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
现在主流的压缩比较强、通用性较高的算法,有 5 种:
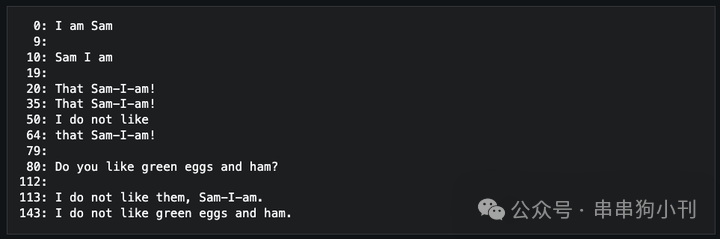
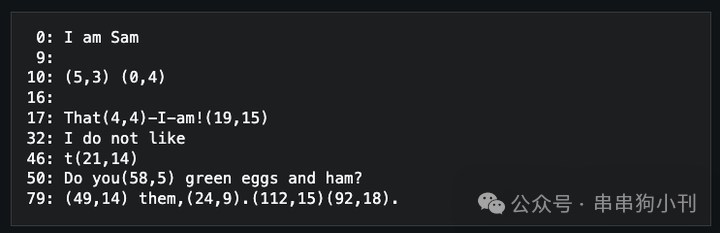
其实这些看着都花里胡哨的,但分开来看,原理都特别简单。 今天用最简单的话给诸位讲一下! 不过很可惜,现在人都不热衷于研究压缩算法了,上面这 5 种肯定不是所有的压缩算法,其实目前这个学科依然非常分散,而且越来越小众了。人们面对现在巨大的科技飞跃储存技术,都没人在乎。更甚,这些东西有很多已经算是失传的东西了。不过,单纯从趣味来说,还是很有趣的。 先说第一个,LZSS 。 这是最古老的算法,全称 Lempel-Ziv-Storer-Szymanski ,是四个科学家的名字连在一起了。 在西天的维基百科上有它的压缩例子: 压缩前:
压缩后:
看到了吗? 压缩器会对重复字符添加标记,待它再次出现时,使用标记(比如 (5,3))来代替。 LZSS 是一个征服世界的压缩算法。原理就这么简单。当然也有点问题,就是这个标记不能随便加,很可能造成数据没压缩,又到处是标记,然后文字大小反而膨胀了。 当然,真正生产环境下的 LZSS 会复杂很多。而上面那问题的解决方案也很粗暴:如果你的这个标记,长度比原文字还长,那就放弃。就这么简单.... 然后就能防止 【没压缩反而膨胀】 的问题。 然后就是字典编码。 这个更强大,理论上只要字典足够大,那么文件就足够小。 原理很简单,给常用的内容,起一个代号。
然后我们让 <1> 代指 人工智能的发展 <2> 代指 深度学习技术 <3> 代指 带来了 结果就是:
这就是它的基本思想。如果你高兴,你能设置几百个,然后结果会更小。 然后是算术编码! 它的特点是,速度很快,效率很高,性价比很高。它看起来会很复杂,它里面用到了数学。 理论上,极端的案例就是,我们耳熟能详的那个外星人在飞船上刻标记的故事: 外星人,要临走了,地球人要送它厚厚的《知识》,但是外星人搬不走,怎么办?就想了个办法,假设飞船长为 1,那么将这《知识》转为数字编码后,在飞船的某个位置刻下刻度,这个刻度就是 0.112315464... 处,只要外星人回到自己的星球,测量一下,得到这个数值,就能反推整个知识了,大概是这个故事。 这个 算术编码 详细的内容很复杂,但大概意思就是,按照出现概率和长短,给每个句子都划定一个小数,最后留下一串比原文短很多的小数。等解压的时候,根据规则,就能从这一堆数字,反推出原文。 感兴趣可以了解一下。这个算法有点深奥。 动态马尔可夫压缩: 这个与其他几个比起来,有点冷门。它也是一个根据概率学,为基础,搞的一个压缩算法。 其实,原理和我们手机电脑天天用的那个中文输入法差不多。就是根据当前的世界,当前你已经输入的内容,然后预测接下来的内容。就好像天气预报。 这个算法的具体内容,是相当复杂和困难的,资料相当少。 它之所以叫 马尔科夫 压缩,是因为它的算法里用到了 马尔可夫链 这个算法。 这个压缩效果很不错,就是很费内存。 最后是压轴的 霍夫曼编码 。 它是 字典压缩 和 概率 的结合。 和字典压缩不一样的是,它最开始,会先把全文读一遍,把所有字符的出现概率给搞出来,然后在内存里列一个表(或者说 树)。后续的工作,围绕这个表进行。 1 Byte(字节)等于 8 bits(比特),大家知道吧! 现在这个算法会重新分配这 8 bit 了。 这个霍夫曼压缩的工作核心就是,将现有的 8 位字符重新分配为更少的位数。为了优化压缩效果,频率最高的字符被赋予更小的比特值。 大概意思就是这样。 之后,就会产生一个要比原文件小的新的文件。 虽然它的压缩比不一定有上面的 算术编码 和 马尔科夫编码 高,但它占用内存很低,速度很快,效果还可以。它一样很古老,是 1952 年被发明出来的。 本文,旨在用最简单的话,把常用的 5 个压缩算法讲一下,如果大家对细节感兴趣,可以在网上寻找它们的资料。不过,这些资料可能会很少,最好还是看 维基百科 或者问 AI 。 这方面的学问,一点不比造操作系统、编译器低。 阅读原文:原文链接 该文章在 2025/12/12 9:22:34 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886