面试官:分库分表有什么好的方案?
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
前言大家应该都知道一些哈希算法,比如MD5、SHA-1、SHA-256等,通常被用于唯一标识、安全加密、数据校验等场景。除此之外,还有一个哈希算法是用于快速定位、分库分表数据分配等场景。本文将以分库分表为主题,介绍另外一种哈希算法,并详细说明其在分库分表中的应用与优势。 分库分表方法在对数据进行分库分表时,通常有两个策略(这里主要说的是水平分库分表):
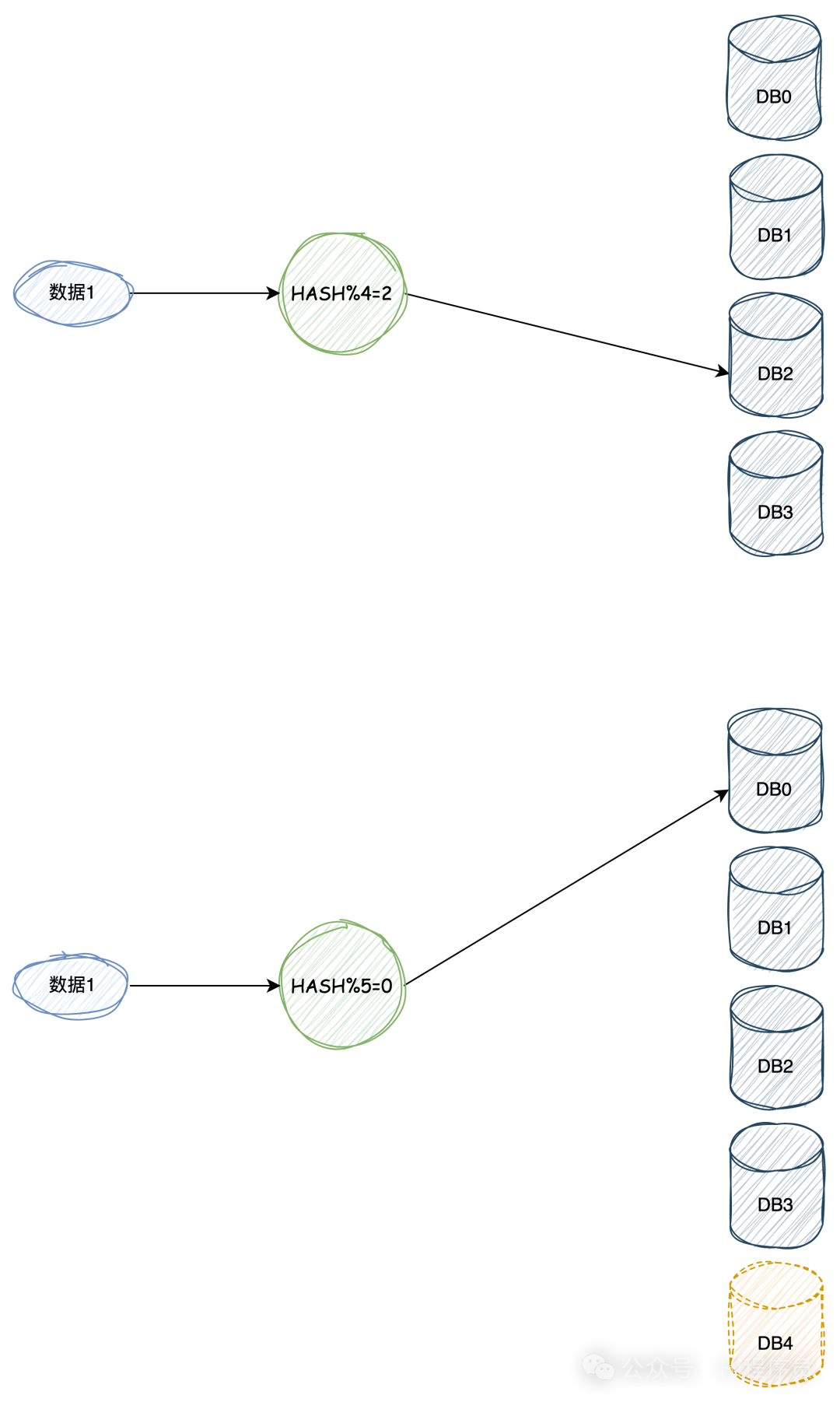
如下图,在添加“DB4“后,数据再次进行hash后会映射到“DB0“上,如果不迁移数据就会出现问题。
很显然,以上两种方法都存在问题,但是哈希这种方法更能体现分库分表的作用,但是带来的代价是全量数据的迁移,需要考虑迁移带来的风险,比如,迁移之后的数据一致性、完整性等各种因素。 那有没有方法可以避免迁移,答案是没有的,只要是使用哈希这种方式,在改变模个数后一定是要迁移数据的。 但是有一种方法可以降低迁移量以及带来的风险,那就是一致性哈希。 一致性哈希介绍一致性哈希算法是一种特殊的哈希算法,通常用于分布式系统中,比如分布式缓存、分布式数据库等解决数据的分配和负载均衡的场景。 与其他哈希算法一样,具有单向性、离散性、平衡性。不同的是,一致性哈希算法在取模时这个模足够大,比如 Fowler–Noll–Vo (FNV) 哈希函数,就是是一种高效、分布均匀的哈希函数,其模数也就是输出域在0~2^32^-1区间。 原理 其原理是将输出域构成一个环,数据和节点通过一致性哈希算法后映射到环中的某个点。 当需数据插入某个节点或查找数据在某个节点时,这个数据对应的哈希值只需在这个环上顺时针找到第一个节点进行操作即可。当节点数量改变时,只需要重新分配一小部分数据即可,从而降低数据迁移风险。 分库分表的应用以分库分表为例子。 如下图,共有3个节点(也可以理解成3个数据库实例),经过一致性哈希算法后映射到输出域中的某个点。 图中的“数据1”经过相同的一致性哈希算法后也会映射到环中的某个点,这个时候如果要存储或者查找该数据就需要顺时针找到第一个节点,也就是“节点2”。 
如下图,当添加“节点4“后,只需要将“节点2“中的部分数据迁移到“节点4“中。 就是将“节点2“中的哈希值大于“节点3“小于等于“节点4“的数据迁移到“节点4“中,其它节点数据则不用迁移。 这样在分库分表中就最大程度减少的数据的迁移,也降低了迁移数据的风险。 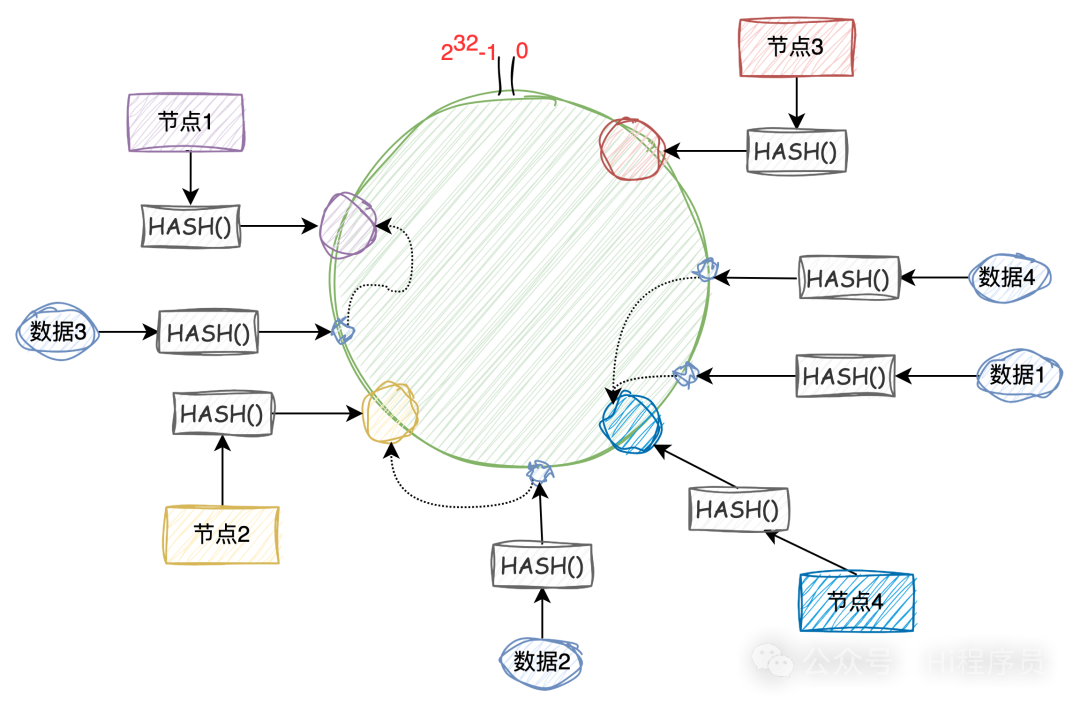 虚拟节点 通常在进行分库分表时我们的节点个数时有限的,前期可能如图1的分布一样,由于节点在环中分配不均匀,数据映射到环中也不均匀,就会有大量的数据会分布到“节点2”中,同样会造成数据倾斜问题。 怎么办?那就让节点分布均匀,这时候就要引入虚拟节点了。 就是说真实的节点虽然只有三个,但是我们可以让每个节点作为大节点管理1000、10000、100000个虚拟的节点,使得每个大节点在环中分布均匀,如下图。  这样,根据哈希的平衡性,数据会均匀的分布到3个大节点中,如果需要添加一个大节点,同样是分发给虚拟节点到环上,然后根据迁移规则进行部分数据的迁移。 总结一致性哈希算法在分库分表的应用中提供了一种高效、均匀且易于扩展的数据分布方式,同时在节点增减时最小化数据迁移成本,是一种还不错的分库分表方案。 该文章在 2024/4/28 20:56:03 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886