深入理解一致性Hash和虚拟节点
当前位置:点晴教程→知识管理交流
→『 技术文档交流 』
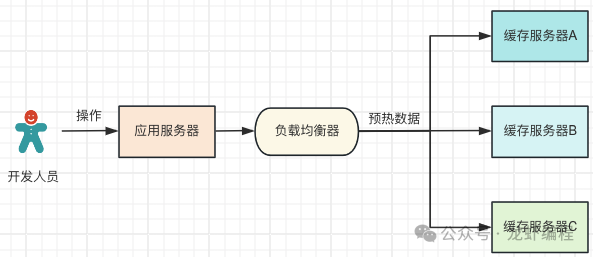
在分布式系统中架构中我们经常提到一致性哈希算法,那么什么是一致性哈希算法,为什么需要一致性哈希算法呢? 1、为什么需要一致性哈希算法 假设现在有三台缓存服务器(缓存服务器A、缓存服务器B、缓存服务器C),现在将数据预热到这三台服务器,我们可以使用负载均衡的方法将数据缓存到服务器上,如下图所示:
通过负载均衡的方式可以把数据均匀的分发到三台缓存服务器上,在读取缓存的热点数据就存在一定的困难(因为不清楚数据被缓存在那台服务器上),读取数据的过程如下所示:
通过轮询缓存服务器的方式读取缓存的热点数据,此时效率就非常的低了,接口的响应时间也会变长,从而导致用户的体验非常差。 负载均衡的方案致命的缺点是无法快速的定位数据在哪台服务器上,导致需要轮询服务器来获取数据,为了解决这个痛点便提出使用Hash算法。Hash算法的预热数据的流程如下图:
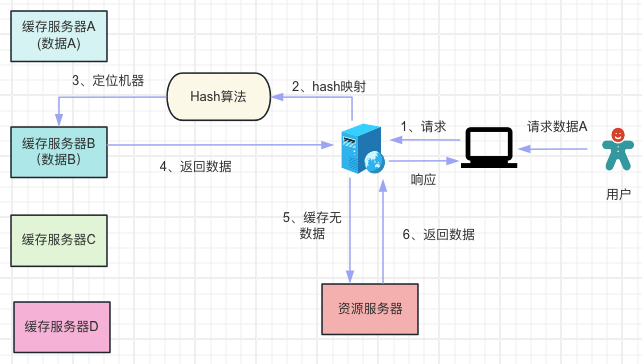
将数据的key计算一个hash值,然后将这个hash值和服务器的台数取模,取模之后的结果就决定当前的数据存放在哪台服务器上。获取数据的流程如下:
读取数据的时候,将数据key同样方式获取hash值,然后将hash值与服务器的台数取模来定位数据在哪台服务器上。但是hash法也存在一个严重的缺陷,假设现在增加/减少服务器数据量,如下图所示:
我们继续使用:hash(key)% 服务器数量,来定位数据在哪台服务器就存在问题了,因为服务器数量变化导致原先数据定位不准,如下所示:
假设现在有大量的请求打进来,由于命中缓存服务上没有数据,请求都落到了资源服务器上,由于资源服务器瞬间压力过大可能会导致服务崩溃。 hash随着服务器的数量变化(增加或减少),定位服务上的缓存的数据位置也会变动,就会导致无法获取数据的问题。为了解决这个问题便提出了一致性hash算法。 2、一致性hash和虚拟节点
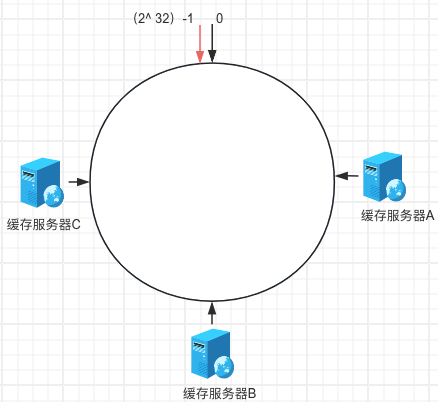
一致性hash算法是对2^32方取模,从0-2^32方计数形成一个圆环,我们称这个圆环为hash环。 通过hash(服务器的ip) % 2^32 = X;通过这个X值可以定位服务器在圆环上的位置。 如何确定数据存放在哪个服务器上呢?如下图所示:
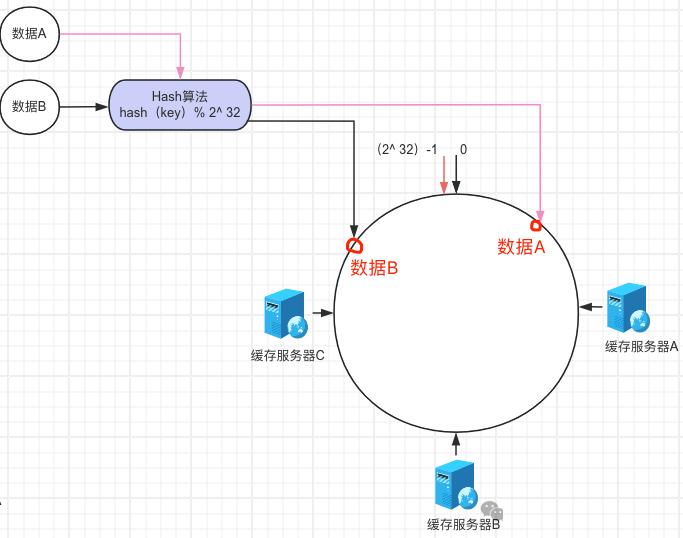
如上的数据A,我们可以使用hash(数据A) % 2^32 = LA;通过LA可以定位数据A在圆环上的位置,然后顺时针方便找距离数据A最近的服务器,发现是服务器A,那么我们将数据A存放到服务器A上。同理数据B也是存放在服务器上A上。 读取数据也是同样按照hash算法取模的方式来定位服务器,通过这样的方式可以很快地定位数据在哪台服务器上。如下所示:
假设现在服务器C下线了,如下所示:
此时数据A定位是没有问题,数据C从原先的服务器C上定位到服务器A上,数据C是无法获取到的。换句话讲,虽然服务器C下线了,但是只是部分数据异常,不会使得整个服务集群数据错乱,数据异常的部分如下所示:
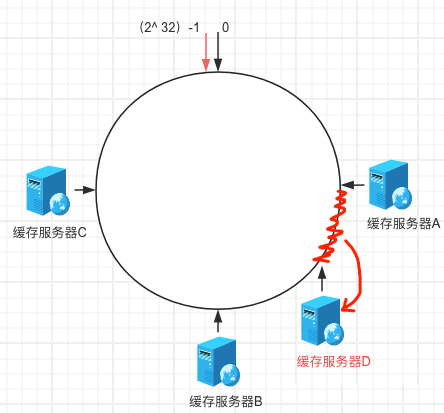
假设现在增加了一台机器D,那么也只会导致部分数据出现错乱,如下图所示:
此时我们只需要将错乱的这一部分数据迁移到服务器D上可以实现数据的同步了。理想状态下,一致性hash是很完美的,但是在极端的情况下由于离散型差的问题导致服务器都集中分布在一起,如下图所示:
此时数据又刚好落在服务器C和服务器A之间的区域上,如下图所示:
这样就导致所有的数据压力都到了服务器A上,服务器B和服务器C就是一个摆设了作用了。如果服务器A挂了,那么整个缓存就失效了,这个就是hash环的倾斜问题。为了解决hash环倾斜问题,于是便引入了虚拟节点,也就是把真实的服务器通过虚拟化的方式复制一些节点出来成为虚拟虚拟节点。如下图所示:
通过虚拟节点的加入就不会导致所有的数据都到一台机器中,同时虚拟节点越多,缓存数据越均匀。 总结: (1)一致性hash常用于负载均衡、分布式缓存分区、数据库分库分表等场景。 (2)为防止服务器上的数据倾斜问题,通常增加虚拟节点的方式来让数据更加均匀的分布在机器上。 该文章在 2024/7/22 9:30:22 编辑过 |
关键字查询
相关文章
正在查询... 



|


 400 186 1886
400 186 1886