SQLite 开发团队于 2024 年 10 月 21 日发布了 SQLite 3.47.0 版本,我们来了解一下新版本的改进功能。
触发器增强
SQLite 3.47.0 版本开始,触发器函数 RAISE() 的 error-message 参数可以支持任意 SQL 表达式。在此之前,该参数只能是字符串常量。
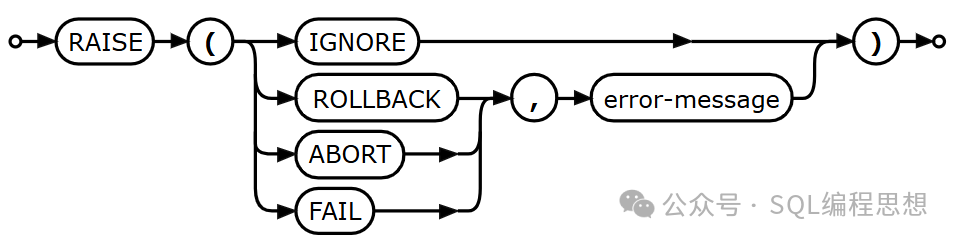
新版本的函数可以输出更加灵活有用的错误信息。
JSON运算符
新版本的 JSON 运算符 ->> 支持从数组右侧开始计算元素下标,例如:
sqlite> select '[1,2,3,4]' ->> 1;
2
sqlite> select '[1,2,3,4]' ->> -1;
4
当表达式右侧参数为负数时,表示从右侧开始开始计算元素位置。
SQL函数
新版本改进了聚合函数 group_concat(),当输入参数只有一行空字符串时返回空字符串而不是 NULL。
sqlite> CREATE TABLE t(cid int, val varchar(10));
sqlite>
sqlite> INSERT INTO t values(1, 'S'),(1, 'Q'),(1, 'L');
sqlite> INSERT INTO t values(2, '');
sqlite> INSERT INTO t values(3, null);
sqlite>
sqlite> .nullvalue 'None'
sqlite> SELECT group_concat(val)
...> FROM t
...> GROUP BY cid;
S,Q,L
None
新版本增强了表值函数 generate_series(),可以识别并且使用基于返回结果值的约束。
性能优化
SQLite 3.47.0 性能优化包括:
优化了 IN 运算符中的子查询重用,尤其是存在谓词下推导致的 IN 运算符重用。
针对 IN 运算符中的子查询,在可能带来优化性能的场景时使用布隆过滤器。
对于类似“SELECT func(a) FROM tab GROUP BY 1”的查询,确保每行数据只调用一次 func() 函数。
如果已知某个字段的选择性很低(通过分析该字段参与的其他索引获得),基于该字段的查询不会尝试创建自动索引(查询时索引)。
针对涉及大量维度表的星型查询优化了查询计划。
增加了排序子查询(order-by-subquery)优化功能,当查询最终的排序结果和子查询中的 ORDER BY 结果一致时,可以避免最终的排序操作。
针对表达式索引,如果查询计划器可以确认不会使用表达式的子类型,indexed-subtype-expr 优化就会尽量使用作为索引一部分的表达式的数值,而不会基于表中的数据重新计算表达式。
其他优化运行速度的代码调整。
命令行工具
SQLite 3.47.0 增加了一个试验性质的命令行工具 sqlite3_rsync,它可以用于实现 SQLite 主从复制。显然这是一个非常重要的功能,可以完成 SQLite 原生一致性复制,期待正式版本。
命令行工具默认增加了扩展聚合/窗口函数 median()、percentile()、percentile_cont() 以及 percentile_disc()。
命令行工具增加了一个元命令 .www,它等价于“.once -w”,可以将查询结果以 HTML 表格形式在浏览器中显示。
sqlite3_analyzer 工具可以获取 WITHOUT ROWID 数据表的详细统计信息。
当数据库比较工具 sqldiff 第二个参数指定的数据库不存在时,不再创建一个空白数据库。
其他改进
修复了非主流 unix-dotfile VFS 回滚热日志文件时存在的一个问题。
即使使用了没有注册的非标准分词器,也可以删除 FTS5 数据表。
通过 ALTER TABLE ADD COLUMN 语句新增非空且存在默认值的字段时,可以识别更新前的钩子程序。
增强了 sqlite_dbpage 虚拟表,INSERT 语句可以用于增加或者减少数据库文件大小。
SQLite 不在使用 long double 数据类型,因为支持该类型的硬件越来越少,而且一些编译工具链无法支持。
新版本支持的 TCL 接口升级为 TCL 9。虽然 TCL 8.5 以及更高版本可能正常工作,但是不能保证,建议升级到 TCL9。
新版本还修复了 JavaScript/WASM 相关的一些问题。同时还改进了 FTS5 相关功能。
完整的发行说明可以参考官方文档:
https://www.sqlite.org/releaselog/3_47_0.html
该文章在 2024/10/24 9:25:11 编辑过






 400 186 1886
400 186 1886


