中文编码之GB2312
|
admin 2025年4月17日 22:53
本文热度 1691
2025年4月17日 22:53
本文热度 1691
|
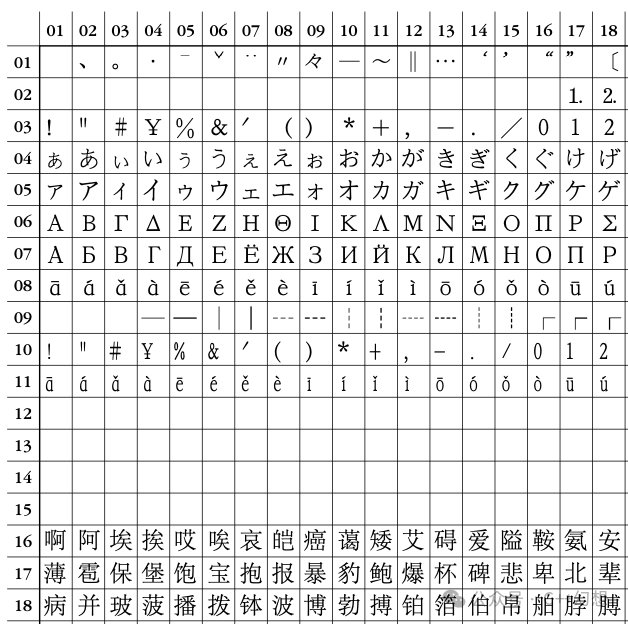
中文编码方案中最有名的就是GB2312,它是中国国家标准总局于1980年发布,并于1981年5月1日实施的。除中国外,新加坡等地也采用此编码。可以说GB2312是中文编码的基石,后续基本都是对它的补充和升级。它共收入了6763个汉字,包括一级汉字3755个(最常用的),二级汉字3008个(比较常用的)。同时收入了拉丁字母、希腊字母、日本片假名、注音符号、西里尔字母等总计682个字符。之前介绍的泰国字符集和欧美字符集都是使用16×16的表格,GB2312也是类似的,但是因为它的字符数量非常多(和欧美等相比),所以它使用的是一个94×94的表格。GB2312编码的每一个字符都在这个表格里,为了方便,这个表格的行号我们称为区码(从1开始),列号我们称为位码(从1开始)。这实际上就是每行是一个区。连续的几个区因为保存的字符的关联性,我们又把把所有区分为了几个区段:
- 01~09区:用于存放拉丁字母、希腊字母、日本片假名、注音符号、西里尔字母等总计682个字符。注意,原则上一个有846(94×9)个位置,但只使用了682个。
- 10~15区:空区,预留,为后续扩展。但实际上,10区和11区已经使用了(这个内容可以参考附录部分)。
- 16~55区:最常用的、一级汉字,共3755个,按拼音排序(新华字典就是这种排序方式)。
- 56~87区:比较常用的,二级汉字,共3008个,按部首/笔画排序(康熙字典就是这种排序方式)。
- 88~94区:空区,预留。目前还没有启用,估计后续也不会启用了。
下图(图1)为编码的局部示意图(完整的太大了,就不展示了,有需要的可以参考附录部分):上图中,第17行,第6列的字——宝,编码就应该是:区码为17(十六进制为11),位码为6(十六进制为06),所以,“宝”这个字的编码(十六进制)就是11 06。PS: 序列化的含义是,存储化,就是转换为一个连续的内存的过程,文字保存(到磁盘等)和网络传输,使用的都是序列化后的数据。最简单的一个转码方案称为国标码,也叫交换码。转换方法是区码和位码分别加上32,也就是十六进制的20,这样,“宝”这个字的交换码(十六进制)就是13 08。当然,现在最常用的是机内码,也叫内码。转换方法是区码和位码分别加上160(相对于GB2312),也就是十六进制的A0,这样,“宝”这个字的内码(十六进制)就是B1 A6。在现代计算机中,基本使用的都是内码。如果,把一个文件编码为GB2312后,如果内容只有一个字——宝,那么,你用二进制工具打开后,看到的通常都是 B1 A6。内码的本质,要说这个问题,要先说交换码的目的。本文后续部分,说的都是十六进制的数。交换码是为了避开ASCII字符中的不可显示字符(00到1F)和空格(20)。这样,区码和位码都加20,(区码和位码)就避开了它们。这样,区码和位码的有效区间就都是[21, 7E]。注意,有趣的点来了,这个使用7位就可以保存了,而计算机的一字节有8位,那么,把交换码的第8位设置为1,就能和ASCII完美避开了。原来第8位为0,变成1的本质就是加上80。这样,加上20,然后再加上80,这不就是加上A0。目前,看到的GB2312编码实际上都是GB2312编码的内码。总结一下:原始的GB2312编码中,区码和位码的有效区间就都是[01, 5E]。GB2312交换码中,区码和位码的有效区间就都是[21, 7E]。原始的GB2312内码中,区码和位码的有效区间就都是[A1, FE]。在实际的使用中,GB2312通常是使用内码,例如:“宝” 这个字的GB2312编码(十六进制)就是 B1 A6,而不会称GB2312内码,或者真的转为GB2312编码的 11 06。真正的GB2312(内码)也已经很难看到了,更常见的是GBK(哪怕是GB2312,也可能标识为GBK)。下次,我们就一起看一下GBK编码。
阅读原文:原文链接
该文章在 2025/4/18 11:49:56 编辑过






 400 186 1886
400 186 1886